Identification of spam sms text messages
This was a project to build a computational model for classifying sms text messages as either spam or not (known as ham).
In the solution presented here the emphasis was put on simplicity. The computational model should be human interpretable. The results should be presented such that a non technical audience can understand without known too much background to the technologies involved.
There are two main tasks in this work. The first is to product some descriptive statistics about the data set. The second is data modelling which involves building and validating the model which will be used for classification.
Data Description
The data description highlights characteristics of the data which can be important for understanding what might effect the model. The sms text data was tokenised and then words were: (1) converted to lower case, (2) punctuation was removed, (3) stop words were removed, (4) single character words were removed and (5) numbers were removed.
The total number of instances was 5572 with the number of spam = 747 and the number of ham = 4825.
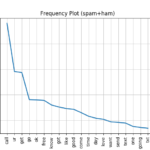
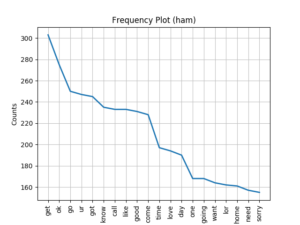
Frequency plots were produced to show the most common words in the full set of sms text messages (spam+ham), the spam and ham messages.
Using this information it can be seen that the spam text typically contains words like free, prize, claim, urgent.

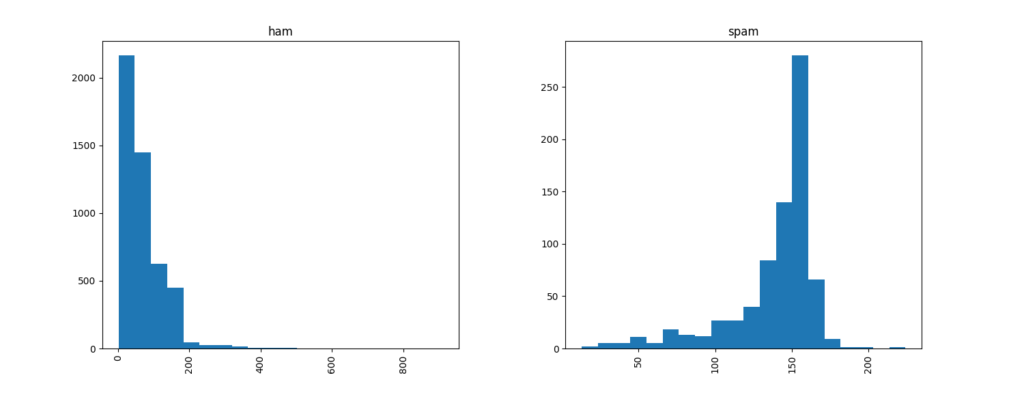
The distribution of the number of words in the spam and ham data sets were also produced to show spam typically has more words per sms message than ham.
Data Modelling
The first part of the data modelling stage was to create a very simple model for classification using a vector space model representation of words. This was conducted using a so called (1) BOW (Bag Of Word) which uses the probability based on the frequency of words in the messages, and (2) TF-IDF based on the inverse frequency of a word in the message.
The results for both the BOG and TF-IDF methods are shown below after 10-fold cross validation as been applied.
| Precision | Recall | Fscore | Accuracy | |
|---|---|---|---|---|
| TD-IDF | 0.8869535653 | 0.7029907266 | 0.7840001773 | 0.9471566739 |
| BOW | 0.8889072411 | 0.5877488209 | 0.7066148344 | 0.9355864627 |
The text pre-processing for this method was extended to include stemming and bi-grams. The results suggest that there is minimal performance difference between the TD-IDF and BOW methods. The text that is typically contained in an sms are short in length, hence the name, short messaging service. As a result, the inverse document frequency does not see any significant gains. It is suggested that applying the TF-IDF method to longer text documents would yield a more significant increase in performance.
Hierarchical Clustering
The second part of the data modelling stage was to use a hierarchical clustering algorithm with an agglomerative (bottom-up) implementation. This means that each word is placed in its own cluster, and clusters are merged based on similarity (eg. euclidean) until all words are in a single cluster. The result is a human readable hierarchy.
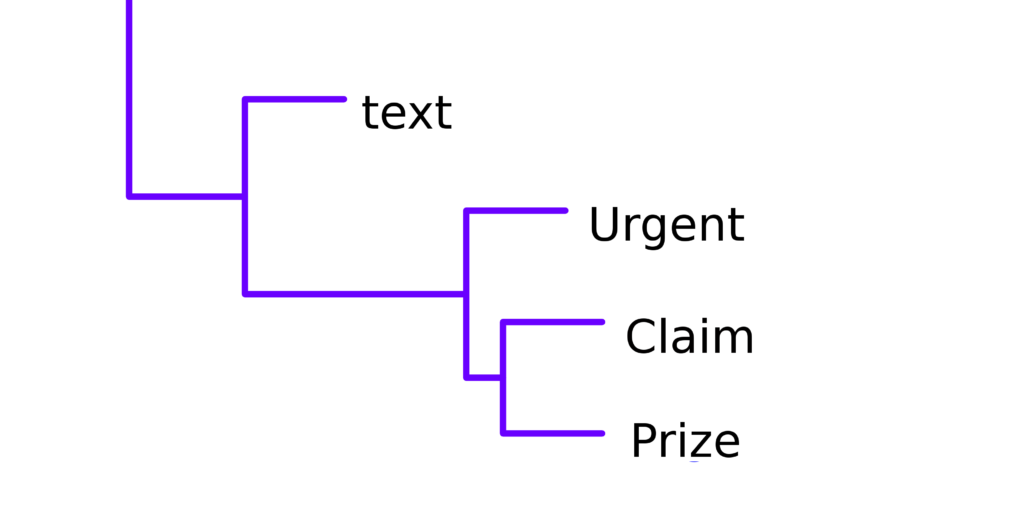
The resulting dendrogram can provide insight into message organisation and categorisation. An example is shown above. It is noted that this diagram is provided for discussion only. The diagram shows the potential to identify that the words claim and prize are highly correlated, closely followed by the term urgent.
The rational behind proposing the hierarchical clustering method was because it can:
- Be useful to determine organisation of sms messages
- Produce categorises for messages
- Be used in unsupervised setting. For large document collection without training
- Is human interpretable
Data set
Reference to data set used in this work
https://archive.ics.uci.edu/ml/datasets/sms+spam+collection#
http://www.dt.fee.unicamp.br/~tiago/smsspamcollection/